
Drupal 7 is coming to an end soon but that doesn’t mean we’re finished with it yet. We created a Drupal application that turns a database of over 1900 definitions into an attractive and informative PDF dictionary in less than 60 seconds!
The main challenge to automating the process was keeping as much flexibility as possible. First, we tackled four informational pages that begin the PDF. We created a Drupal form to capture that content using HTML text fields and placed each field on its own tab to reduce page scrolling and make editing easier (and it also looked better).

Processing is all in the wrist!
Once all the preface pages are entered and submitted, the application goes to work. Most of the work is done with FPDF, a PHP class that we use to generate the actual PDF file. But we had to get creative with how we used it. If we tried to generate the dictionary all at once, the amount of processing and memory needed would most likely freeze the web server. To avoid this, we used Drupal’s built-in batch processor to break the creation of the PDF up into smaller chunks that run in the server’s background.

The first batch starts the PDF with a cover and adds the preface pages submitted with the Drupal form. FPDF provides a basic HTML converter that only processes line breaks, links, and basic text. We expanded the code to add three different header styles, paragraphs, horizontal rules, block quotes, embedded images, bulleted and numbered lists, description terms (<dt>) and description details(<dd>). Whew! By defining custom fonts, colors, padding, and margins for every element we added, we were able to use basic HTML in form fields, but still print the PDF elements correctly.

<h2>Context Hierarchy</h2> <br /> <p>Most of the terms in this dictionary have meaning primarily in specific contexts (e.g., SCSI or File Systems). The following categories are used to specify the context for a given definition. These categories are a guide to understanding, not a formal system.</p> <br /> <br /> <p><img alt="" height="348" src="data:image/png;base64,..." width="540" /></p> <p>In the above hierarchy representation, context labels indented beneath other context labels represent specializations of the higher-order label concept. For additional information on contexts, see the Storage Industry Resource Domain model. Below is an example of how context is indicated:</p> <blockquote> <div><strong>term name</strong></div> <div>[Context] The context is called out in square brackets at the beginning of each definition, as in this example.</div> </blockquote>
HTML input / PDF output
Print. Rinse. Repeat. Well, mostly.
Once the preface pages are printed, the processor loops through and adds each term of each letter of the alphabet as a separate batch. The letter being processed is tracked so each time the letter changes, the PDF automatically breaks to a new page and the new letter is printed as the page heading. Each term block (the term, its associated categories, and its description) is printed to the PDF.

To prevent ugly text wrapping issues, the PDF also needs to break to a new page when a term doesn’t fit completely at the bottom of a page. However, one quirk in printing PDFs this way is that there is no way to know if a given description will fit until it is printed AND printed elements cannot be removed after they’ve been printed. Somehow, we need to know that a term block didn’t fit before we printed it.
After some thought, we came up with a simple solution. The processor would make a temporary copy of the PDF and add the term block to this test PDF first. Then, if the number of pages in the test PDF increased, we’d know that the block is too big for the page and break to a new page before actually printing the term.
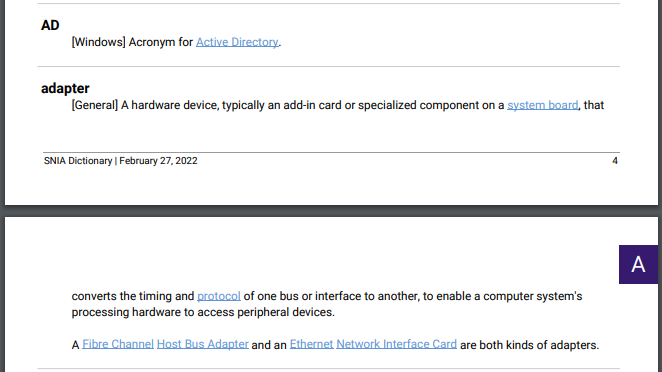
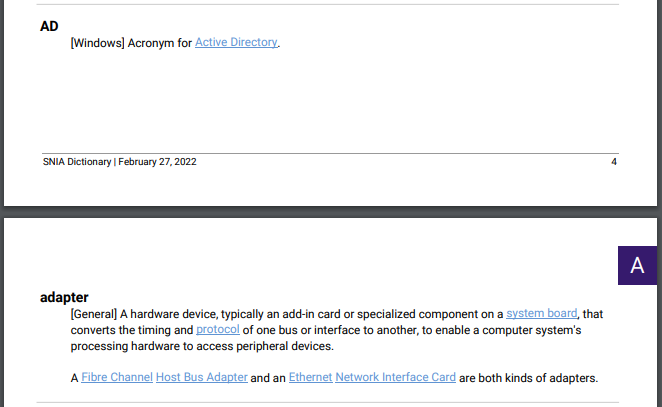
Smart wrapping before and after
Viola! A 300 page dictionary!
After all terms have been printed, the application completes the PDF with a back cover containing social media links. Finally, the processor adds bookmarks, one for each page or section title. The PDF is saved to the location defined in the form and return to the application’s frontpage with a link to the completed PDF.

Check out our auto-magically created SNIA Dictionary PDF! We’ve done something like this before, if you’re interested.


